How to Reduce AI Inference Latency Effectively
Introduction
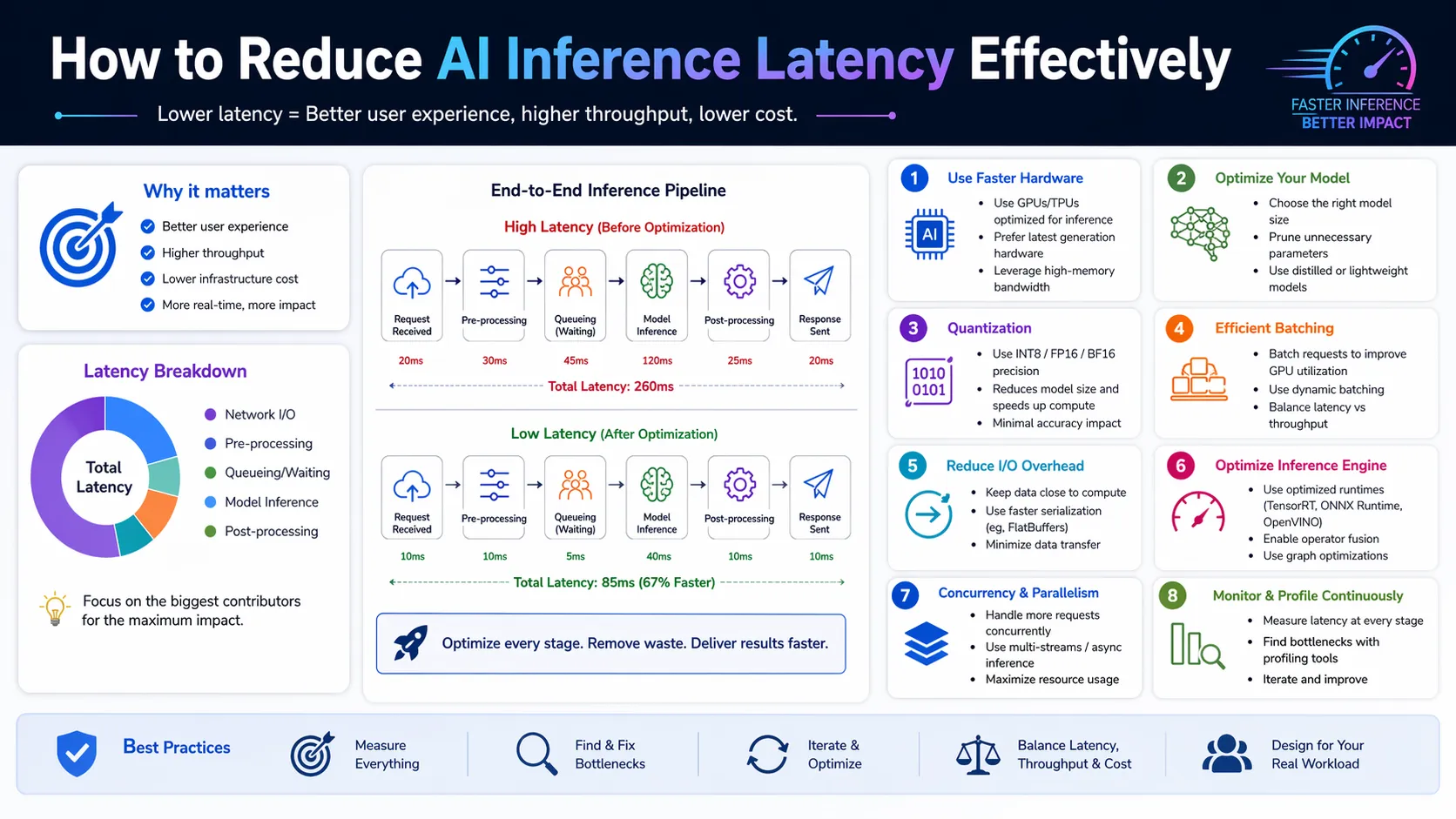
Understanding how to reduce AI inference latency effectively drives modern machine learning success. Businesses need rapid model responses today. Delays destroy user retention immediately. High latency also drastically increases computational overhead costs. Knowing how to reduce AI inference latency effectively solves both critical business problems. Optimization is essential. AI inference latency is the time a neural network takes to return a prediction. Teams must learn how to reduce AI inference latency effectively to scale.
The primary entity here is the AI inference pipeline. This pipeline translates user inputs into actionable model outputs. Speed defines pipeline efficiency. Supporting entities include GPUs, memory bandwidth, model weights, and compute clusters. Every component must synchronize perfectly. Bottlenecks in one area slow everything down. Organizations cannot rely on raw compute power alone. Intelligent architecture design matters more than brute force. Strategy outperforms simple hardware throwing.
Slow models ruin customer experiences entirely. Users abandon applications that take seconds to load. Milliseconds determine commercial success now. Evaluating current system limitations is the first step. Identify where the data stalls. Measure network, compute, and memory delays separately. This guide provides a comprehensive framework. It outlines actionable steps for developers and strategists. Follow these principles for massive performance gains.
How to Reduce AI Inference Latency Effectively
Hardware Acceleration Integration
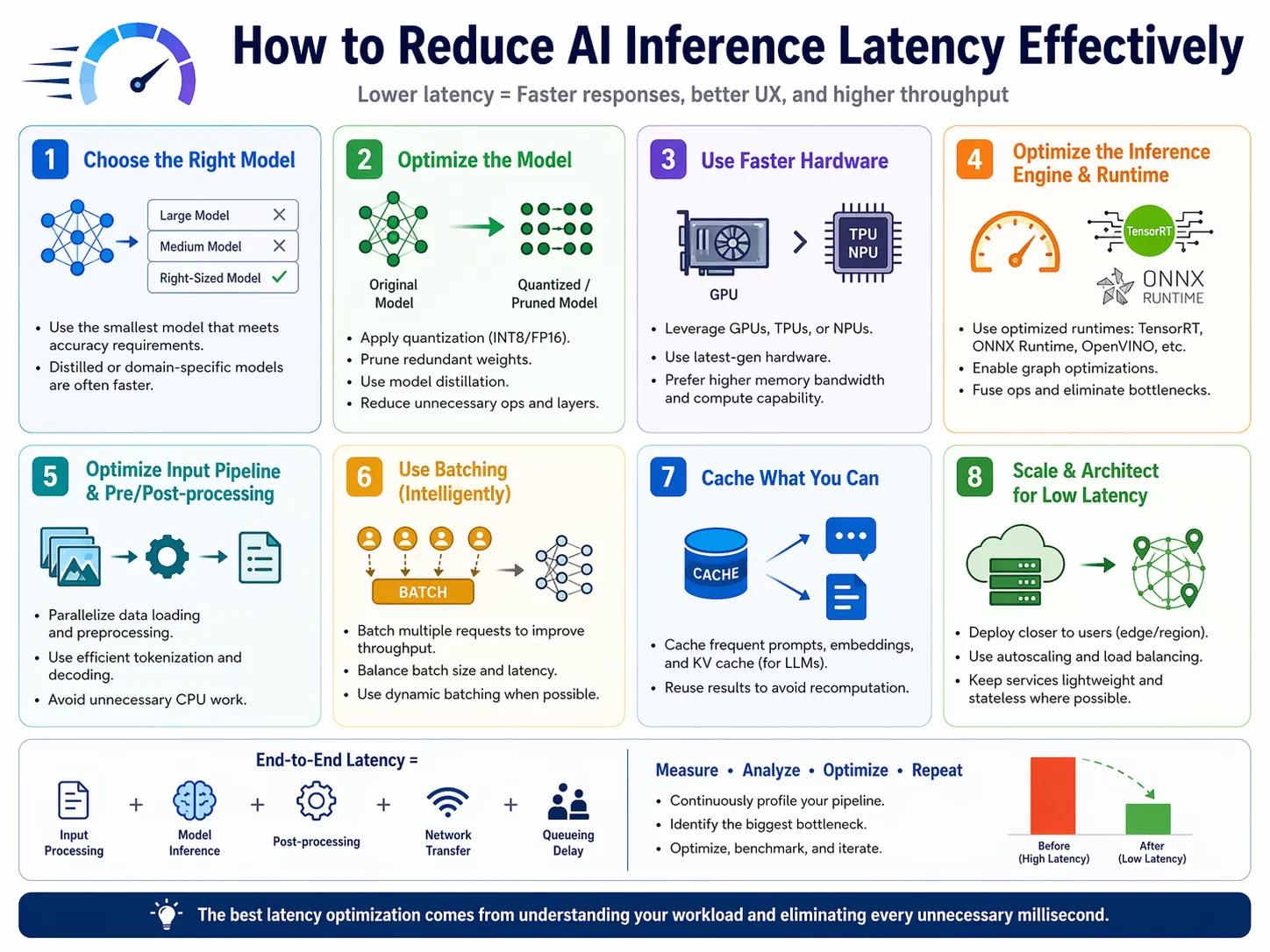
Processing hardware dictates base execution speed. Standard central processors struggle with complex matrix multiplications. Specialized hardware removes this exact bottleneck. Graphics Processing Units handle parallel tasks efficiently. Tensor Processing Units offer even faster AI workload execution. Upgrading hardware directly improves model serving speed. Specific AI chips contain dedicated tensor cores. These cores perform specialized math operations instantly. They are built specifically for deep learning.
Hardware upgrades provide the most immediate latency reduction. Faster chips mean happier users and higher throughput. This translates to better business margins. Relying on legacy hardware restricts growth potential. Modern models demand modern silicon architecture. Investing in hardware pays dividends through speed. Cloud providers offer scalable hardware solutions. You can rent powerful GPUs on demand. This lowers initial capital expenditure for startups.
Implementing NVIDIA TensorRT optimizes neural network models further. It maximizes throughput on specific graphics hardware. This integration shrinks processing time significantly. Consider a high-traffic e-commerce recommendation engine. Switching to dedicated GPUs drops latency by half. Sales increase as users view suggestions faster. Never underestimate hardware optimization. It forms the foundation of fast AI. Software tweaks sit on top of good hardware.
Model Quantization Techniques
Model quantization reduces the precision of network weights. It converts floating-point numbers into lower-bit representations. This process shrinks the overall model size. Moving from 32-bit floats to 8-bit integers is common. This transformation requires less memory bandwidth. Data moves faster through the system bus. Post-training quantization applies changes after model creation. Quantization-aware training builds precision limits into the training phase. Both methods yield excellent compression.
Smaller models load faster into computer memory. They require less computational power to execute predictions. This directly accelerates AI inference optimization. Reduced precision sounds risky but is remarkably safe. This shift causes minimal, often unnoticeable, accuracy loss. The speed improvements are massive and measurable. Lower memory footprints allow larger batch sizes. You can fit more requests into the same GPU. This maximizes hardware investment returns.
Does quantization degrade user experience? Rarely. Most commercial applications operate perfectly with quantized neural networks. A chat application using an 8-bit quantized large language model responds instantly. Users perceive the AI as highly intelligent and conversational. The slight precision drop is invisible. Engineers must test output quality after quantization. Balance speed gains against acceptable accuracy thresholds. Find the perfect middle ground.
Network Pruning and Sparsity
Network pruning removes redundant connections within a model. Deep learning models often contain unnecessary parameters. Pruning deletes these useless nodes safely. Unstructured pruning removes individual weights randomly based on importance. Structured pruning removes entire channels or layers entirely. Both methods streamline the underlying architecture. Creating sparsity means introducing zeros into the weight matrices. Sparse matrices require fewer active compute cycles. The system skips the zero values entirely.
A sparse model requires fewer calculations per request. Fewer calculations equal faster processing times. This is vital for lowering response delays. Clean architectures perform better under heavy load. Pruned models execute rapidly on modern inference engines. Less data movement means higher throughput. Training a large model and pruning it later works best. It retains the learned knowledge while dropping the bulk. This is highly efficient.
Imagine a visual recognition system for self-driving cars. Pruning removes non-essential visual filters. The car identifies pedestrians milliseconds faster. Those milliseconds prevent physical accidents. Pruning saves lives in critical edge deployments. It makes heavy models nimble and safe. Combine pruning with quantization for compounding benefits. The resulting model is both small and sparse. Speed increases exponentially.
Knowledge Distillation Processes
Knowledge distillation uses a large teacher model. This teacher trains a much smaller student model. The student learns the teacher’s exact output patterns. The student model mimics the complex decision boundaries. It achieves this without needing the massive parameter count. It compresses knowledge intelligently. Distillation transfers soft targets instead of hard labels. These soft targets contain rich contextual information. The student learns nuances quickly.
The student model is inherently faster. It possesses a fraction of the original layers. Inference speed skyrockets immediately. You get heavy-weight performance from a light-weight model. This drastically reduces server hosting costs. It makes advanced AI accessible anywhere. Training the student requires initial compute investment. However, the long-term inference savings justify this cost. It is a smart architectural trade-off.
A financial fraud detection system uses distillation. The massive teacher model runs offline securely. The fast student model evaluates live transactions. The system catches fraudulent swipes instantly at the terminal. Slower models would delay the checkout process. Distillation keeps commerce flowing smoothly. Always consider distillation before deploying massive models. It is the ultimate shortcut to speed.
Intelligent Request Batching
Dynamic batching groups multiple incoming user requests together. Processing requests individually wastes system resources. Batching maximizes hardware utilization rates. The inference engine processes the grouped batch simultaneously. It pushes the matrix through the GPU once. It returns the results to individual users afterward. Systems set strict time windows for batch collection. A typical window might be ten milliseconds. Requests arriving within this window group together.
This method increases total system throughput massively. It prevents the GPU from idling between individual queries. Efficiency hits peak levels. Waiting too long increases individual user latency. Finding the perfect batch window is crucial. It requires careful traffic analysis. High concurrency environments benefit the most. Systems with thousands of active users need dynamic batching. It prevents catastrophic server queuing.
A cloud-based translation API receives constant traffic. Batching processes fifty sentences at once. Overall throughput increases by ten times. Individual users still receive translations in milliseconds. The slight batching delay is imperceptible. The server handles the load effortlessly. Configure your inference server for optimal batch sizes. Test different configurations under simulated stress.
Edge Computing Deployment
Cloud computing introduces network transmission delays. Sending data to remote servers takes physical time. Edge computing brings processing closer to the user. Deploying models on local devices eliminates network round-trips. Mobile phones and IoT devices handle lightweight inference locally. Processing happens directly on the hardware. Specialized edge frameworks compile models for mobile processors. Tools enable this transition seamlessly. They bridge the gap between cloud and edge.
Local processing offers near-instantaneous responses. The application works even without internet connectivity. This creates a superior user experience. Edge deployment secures sensitive user data naturally. Data never leaves the physical device. This solves strict privacy concerns entirely. Server costs drop dramatically. Users provide the compute power via their own devices. This is highly economical for startups.
A smart security camera uses edge AI. It detects intruders instantly without uploading video. Alerts trigger locally in real-time. A cloud-dependent camera would stall during poor connection. Edge computing guarantees continuous operation. Latency drops essentially to zero. Push models to the edge whenever technically feasible. It represents the ultimate latency solution.
How to Reduce AI Inference Latency Effectively
Conclusion
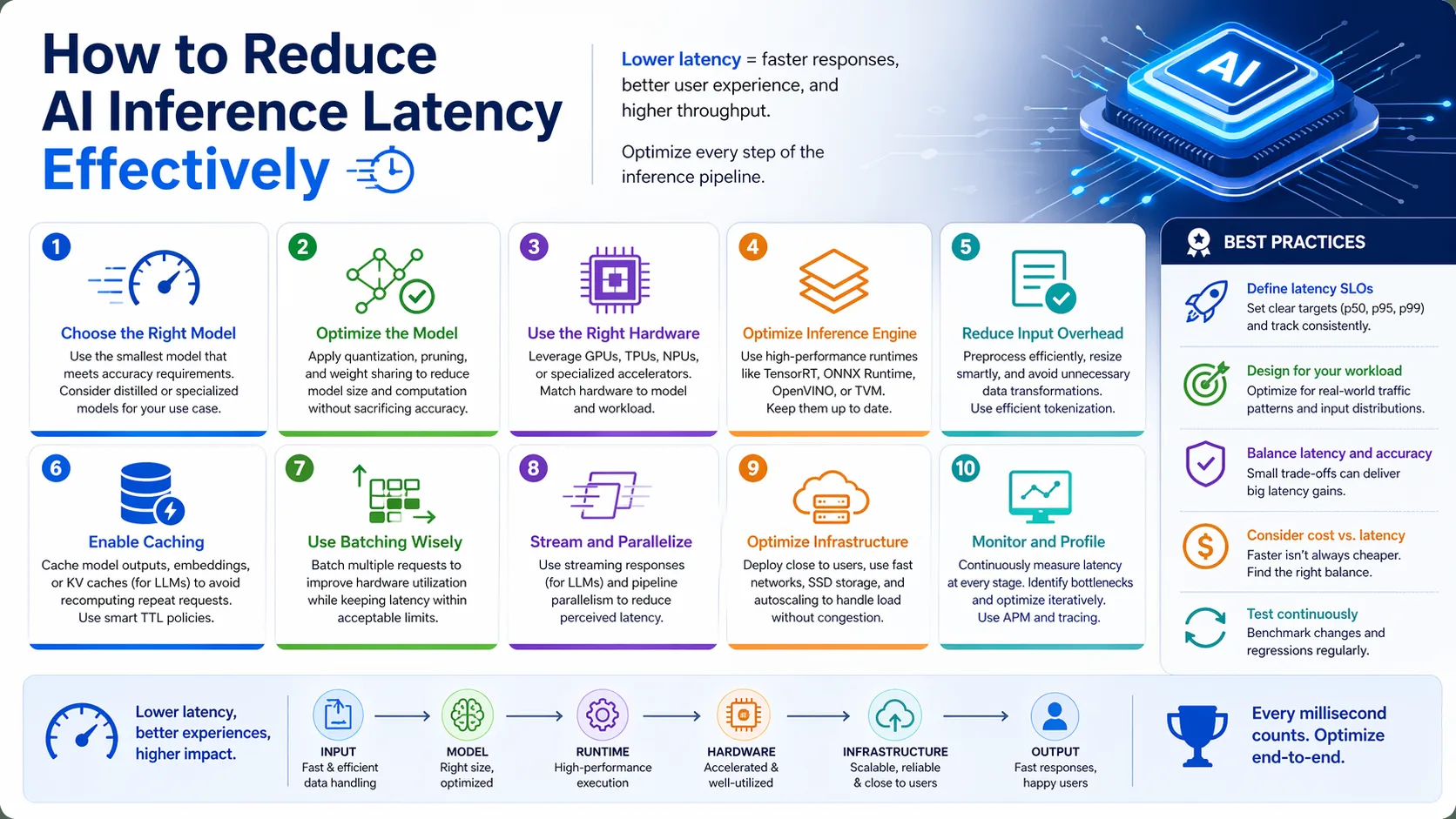
Mastering AI optimization transforms standard applications into industry leaders. Speed defines the absolute future of machine learning integration. Slow models will not survive the competitive landscape. Lowering latency improves user satisfaction and cuts server costs. These techniques represent standard engineering requirements now. You must adapt to these optimized architectures. Implement these optimization strategies today. Build faster, smarter, and more reliable AI systems. Evaluate your pipeline and apply these upgrades now.
FAQS
What is AI inference latency?
It is the exact time required for a trained model to process data and generate a prediction.
How does quantization improve model speed?
Quantization reduces data precision, making the model significantly smaller and faster to process in memory.
Why use edge computing for AI tasks?
Edge computing processes data locally on the device, eliminating network transmission delays and securing user privacy.



{kind=link}