
Machine Learning Vs Deep Learning: Key Differences Explained
Introduction
As we navigate an era defined by data, understanding the critical distinction between Machine Learning Vs Deep Learning is no longer a niche technical skill but a fundamental aspect of digital literacy. While often used interchangeably, these terms represent a foundational hierarchy within AI, each with distinct mechanisms, applications, and strategic weight. This guide provides a clear, actionable framework for professionals to move beyond the buzzwords and make informed decisions.
The core relationship is essential: Machine Learning Vs Deep Learning is a specialized subset. Both reside under the broad umbrella of artificial intelligence, but their philosophy for learning from data differs fundamentally. The strategic choice in any Machine Learning Vs Deep Learning debate is never about which technology is superior in a vacuum. It is a pragmatic decision about selecting the right tool for a specific task, dictated entirely by the nature of your data and the complexity of the problem you need to solve.
Machine Learning Vs Deep Learning: Key Differences Explained
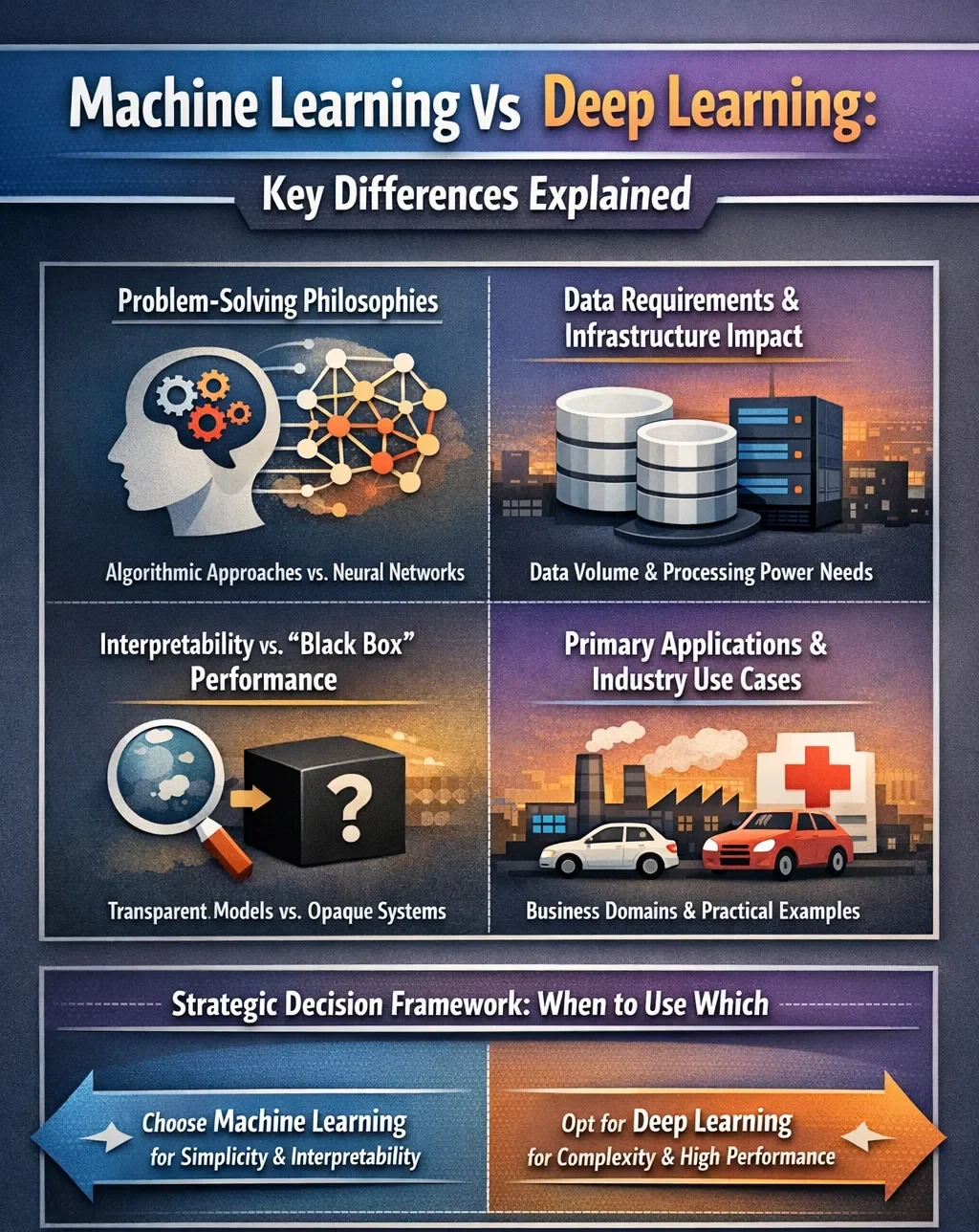
Core Distinctions: Problem-Solving Philosophies
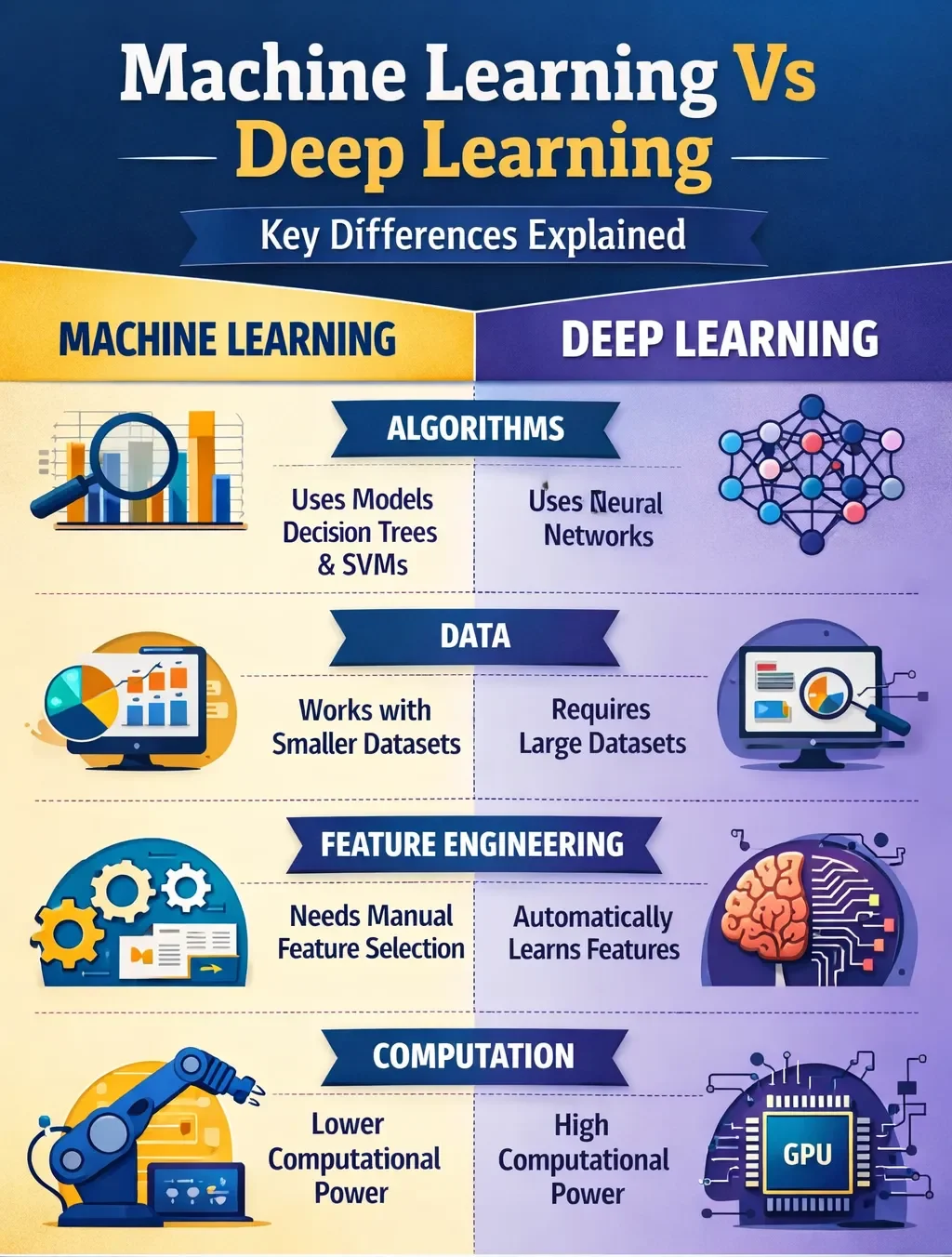
The fundamental divergence lies in how each approach processes information. Machine learning typically requires a human-guided step known as feature engineering. Experts must manually identify and extract the most relevant characteristics (or “features”) from raw data for the model to analyze. For example, to build a model that identifies loan risk, a data scientist might select features like income, credit history, and debt-to-income ratio.
In contrast, deep learning automates this process. It uses architectures called artificial neural networks, inspired by the human brain’s structure, which consist of multiple interconnected layers. These models ingest raw data—such as pixel values in an image or raw audio waveforms—and autonomously learn to identify progressively complex features through their hidden layers. An early layer might detect edges in a photo, a middle layer might recognize shapes, and a final layer could identify a specific object like a car or a face. This hierarchical learning eliminates the need for manual feature engineering.
Data Requirements and Infrastructure Impact
Your available data is the most critical factor in choosing an approach. Machine learning algorithms can deliver strong, interpretable results with smaller, structured datasets—often ranging from hundreds to thousands of well-organized examples. They can often be trained and run on standard computing hardware.
Deep learning models, however, are data-hungry. They require massive volumes of data—often millions of examples—to train effectively and avoid “memorizing” the training set instead of learning generalizable patterns. This hunger for data is matched by a demand for computational power. Training complex neural networks requires specialized hardware like Graphics Processing Units (GPUs) or access to substantial cloud computing resources, leading to higher costs and longer training times compared to traditional ML.
Interpretability vs. “Black Box” Performance
The clarity of a model’s decision-making process is crucial in regulated industries. Machine learning models, especially simpler ones like decision trees or linear regression, are generally more interpretable. You can often trace which features influenced a prediction and understand the logical pathway.
Deep learning models, with their millions of parameters across dozens of layers, are notoriously opaque. They function as “black boxes,” where it is exceptionally difficult to decipher why a specific decision was made. This trade-off—sacrificing interpretability for superior performance on complex tasks—must be carefully weighed, particularly in fields like healthcare or finance where explainability is paramount.
Primary Applications and Industry Use Cases
The practical applications of each technology highlight their ideal use scenarios.
Machine Learning excels at tasks with structured data and clear parameters:
- Predictive Analytics: Forecasting sales, customer churn, or house prices.
- Recommendation Systems: Suggesting products on e-commerce sites or content on streaming platforms based on user history.
- Fraud Detection: Identifying anomalous patterns in financial transactions.
- Process Automation: Classifying emails as spam or automating routine administrative tasks through intelligent chatbots.
Deep Learning dominates domains involving unstructured, high-dimensional data:
- Computer Vision: Enabling facial recognition, medical image analysis for disease detection, and the perception systems in autonomous vehicles.
- Natural Language Processing (NLP): Powering advanced language translation, sentiment analysis, and the conversational abilities of virtual assistants like Siri and Alexa.
- Complex Generative Tasks: Creating realistic images, videos, and music through models like Generative Adversarial Networks (GANs).
Strategic Decision Framework: When to Use Which
Your project’s constraints and goals should guide your choice. Use this framework for evaluation:
Opt for Machine Learning when:
- Your data is structured, labeled, and relatively limited in volume.
- You require a model that is transparent and easy to explain to stakeholders.
- Computational resources are limited, and you need a faster, more cost-effective path to deployment.
- You are building a proof-of-concept or working on a well-defined, traditional analytics problem.
Opt for Deep Learning when:
- You are working with unstructured data (images, text, audio, and video) in its raw form.
- You have access to vast, high-quality datasets and substantial computational power (e.g., cloud GPUs).
- The task involves extreme complexity, such as real-time object recognition or understanding human language nuance, where maximum accuracy is the primary objective.
- Model interpretability is a secondary concern to achieving state-of-the-art performance.
Machine Learning Vs Deep Learning: Key Differences Explained
Conclusion
The choice between machine learning and deep learning is strategic, not hierarchical. Use machine learning for efficient, interpretable solutions with structured data. Choose deep learning to solve complex, perceptual problems with massive unstructured datasets, accepting its “black box” nature and higher resource costs.
The future lies in their integration, not competition. The correct approach is defined by your specific problem, data, and resources. Move forward by applying this practical framework to your next project.
FAQs
Can I use deep learning with a small dataset?
Usually not, because deep learning models need large datasets to perform well. Transfer learning can help when data is limited.
Should I learn machine learning before deep learning?
Yes, learning machine learning first is recommended because it builds a strong foundation for deep learning concepts.
Is deep learning always more accurate than machine learning?
No, deep learning is better for unstructured data, while traditional machine learning often works better for structured data.



{kind=link}