
Federated Learning: Achieving Collective Intelligence
Introduction
Federated Learning is a foundational framework for building powerful AI models without centralizing sensitive data. This approach is not a technical novelty but a strategic response to the hard limits of data privacy and ownership. The core mechanism of Federated Learning is a clear, inverted process: the model travels to the data, learns locally, and only aggregated insights return. This process is being applied across sectors from healthcare to finance to solve a critical, modern dilemma: achieving collective intelligence without compromising confidentiality or control. Adopting Federated Learning principles is increasingly central to creating sustainable, trustworthy, and effective AI systems.

Federated Learning: Achieving Collective Intelligence
The Core Mechanism: Bringing the Model to the Data
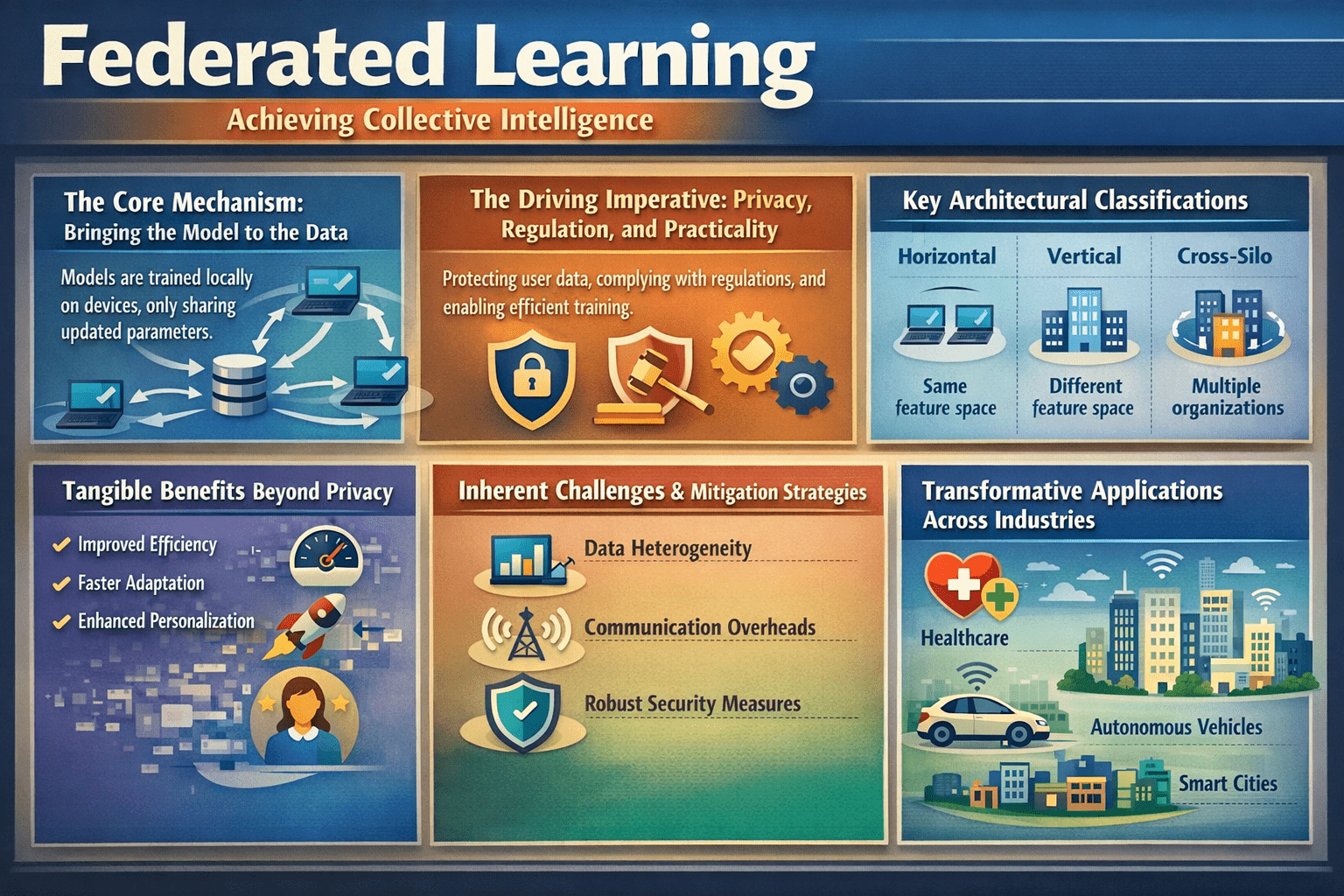
The process of federated learning operates on a fundamental inversion of traditional machine learning. Instead of collecting data into a central cloud for training, an initial model is sent from a coordinating server to a federation of clients. Each client—such as a mobile device or a hospital database—trains this model locally using its own private data. Only the resulting model updates, typically in the form of gradients or weights, are sent back to the server. The server then aggregates these updates to create an improved global model, which is redistributed for further rounds of training. This cycle continues until the model achieves the desired performance. The raw data never leaves its source, preserving privacy while enabling collective learning.
The Driving Imperative: Privacy, Regulation, and Practicality
The adoption of federated learning is driven by a convergence of technical, legal, and business factors. Primarily, it is a powerful response to global data protection regulations like the GDPR, which emphasize principles of data minimization and purpose limitation. By design, federated learning aligns with these principles, keeping personal and sensitive information under the control of the original data controller. Practically, it solves the critical problem of data silos, allowing organizations in sectors like healthcare and finance to pool insights without sharing proprietary or confidential patient and customer records. This enables the development of more robust and generalizable AI models that would be impossible to create with isolated datasets.
Key Architectural Classifications: Horizontal, Vertical, and Cross-Silo
Not all federated systems are alike; they are classified based on how data is distributed among participants. In horizontal federated learning, different clients hold datasets with the same features but different samples (e.g., multiple banks with similar customer transaction records). In vertical federated learning, clients hold different features about the same entities (e.g., a bank and a retailer both holding data on the same customers but with different attributes). Furthermore, systems are categorized as cross-device (involving a massive number of end-user devices like smartphones) or cross-silo (involving a smaller number of organizational clients like hospitals or manufacturers). Understanding these distinctions is crucial for designing an effective federated solution.
Tangible Benefits beyond Privacy
While privacy is the headline advantage, the benefits of federated learning extend further. It significantly improves bandwidth efficiency by transmitting compact model updates instead of massive raw datasets, which is vital for mobile networks and IoT environments. The approach also enhances model diversity and robustness by learning from a wider variety of real-world data distributions, leading to AI that performs better across different populations and scenarios. Furthermore, it enables edge computing by performing training locally on devices, which supports real-time inference and continuous model personalization even with intermittent connectivity.
Inherent Challenges and Mitigation Strategies
Adopting federated learning introduces unique technical complexities. Data heterogeneity, where local data is non-uniformly distributed, can cause model divergence and slow convergence. Mitigation strategies include advanced aggregation algorithms that weigh updates based on data quality. Communication overhead from frequent model updates can be a bottleneck, addressed through techniques like model compression and selective client participation. Security risks also evolve; while data stays local, model updates can be vulnerable to inference attacks or poisoning by malicious clients. Defenses include employing differential privacy (adding statistical noise to updates), secure multi-party computation, and Byzantine-robust aggregation techniques.
Transformative Applications across Industries
The practical applications of federated learning are vast and growing. In healthcare, it allows hospitals worldwide to collaboratively train diagnostic models for rare diseases without sharing a single patient scan, a use case actively promoted by platforms like MedPerf. For mobile and consumer devices, it powers privacy-preserving improvements to features like predictive text, voice recognition, and personalized content recommendations directly on smartphones. In autonomous vehicles, federated learning enables fleets of cars to collectively learn about new road hazards or traffic patterns while keeping sensitive location data on board. Other key areas include financial fraud detection across banks and predictive maintenance in smart manufacturing.
Federated Learning: Achieving Collective Intelligence
Conclusion
Federated learning represents a profound shift in the philosophy of AI development, moving from a paradigm of data centralization to one of collaborative intelligence. It is not merely a technical workaround for privacy laws but a foundational framework for building AI that is both powerful and respectful of individual and organizational data sovereignty. The challenges it presents—in coordination, security, and systems design—are substantial, but the payoff is a more sustainable, trustworthy, and inclusive path for AI advancement. For leaders, the question is no longer if they will encounter federated learning, but when and how they will integrate its principles to unlock value trapped in isolated data.
FAQs
Is federated learning completely secure and private?
While it significantly enhances privacy by keeping raw data local, the model updates shared can potentially leak information. Advanced techniques like differential privacy and secure multi-party computation are often layered on to provide stronger guarantees.
What is the difference between federated learning and traditional distributed training?
In traditional distributed training (like in a data center), data is partitioned but still centrally controlled and physically accessible. In federated learning, data is fundamentally decentralized, owned by different entities, and never pooled in one location.
Does federated learning work with modern large language models (LLMs)?
Yes, through a process known as federated fine-tuning. Enterprises can adapt foundation models like Llama or Gemini to their private, domain-specific data without ever exposing that data to the model provider.



{kind=link}