
Introduction
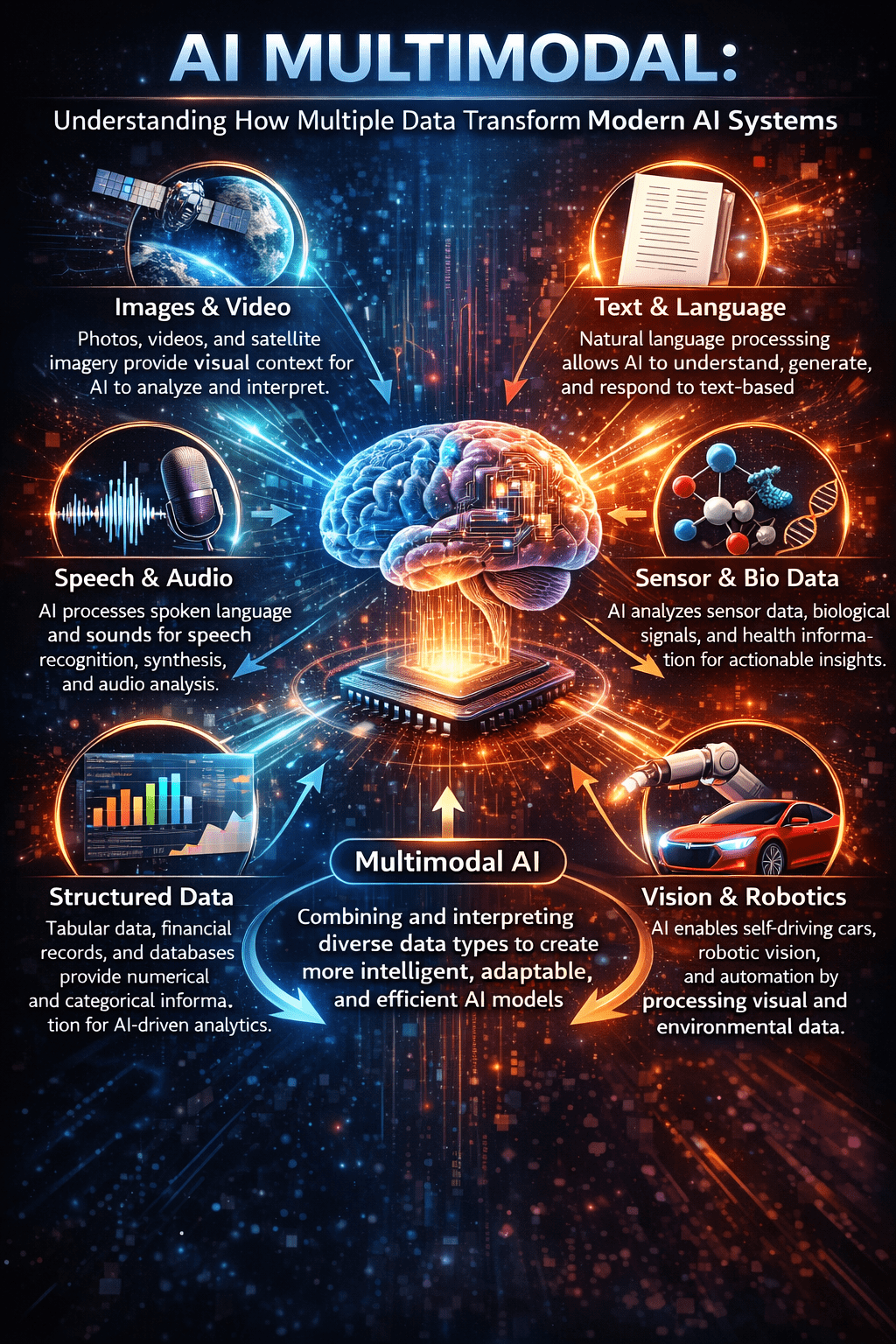
AI Multimodal refers to intelligent systems that can interpret and generate meaning from more than one type of data, such as text, images, audio, and video. AI multimodal systems combine these input types to produce more informed and context-aware outputs, making them far more capable than single-mode systems restricted to text alone. AI Multimodal platforms are increasingly critical because they mirror the way humans process the world—using multiple senses to understand context and nuance. In today’s digital ecosystem, understanding AI Multimodal is essential for professionals seeking deeper insight into practical machine intelligence that goes beyond traditional text-only models.
What Is AI Multimodal?
AI multimodal refers to artificial intelligence systems designed to understand and generate responses across multiple data inputs simultaneously. Unlike conventional models that specialize in one format, multimodal AI integrates different information streams into unified comprehension.
The term “modality” describes each distinct data type—visual data from images, textual information from documents, audio signals from speech, and sensor data from devices. When these modalities combine within a single AI framework, the system gains contextual depth impossible through isolated processing.
How Does Multimodal AI Work?
These systems operate through specialized encoders that convert each data type into numerical representations called embeddings. Text encoders transform words into vectors, vision transformers process image patches, and audio encoders analyze sound waves.
The critical innovation occurs in fusion layers, where these separate representations merge through cross-modal attention mechanisms. When processing an image alongside a text question, the system identifies which visual regions correspond to words in the query.
Training relies on contrastive learning with massive paired datasets. Models learn to associate matching combinations, like images with captions, while distinguishing mismatched pairs. Through billions of examples, networks develop internal spaces where related concepts cluster together regardless of original format.
Healthcare Applications
Healthcare facilities deploy multimodal systems combining patient records, medical imaging, and clinical notes. These platforms identify patterns that single-source analysis might miss, supporting diagnostic accuracy.
Physicians access systems correlating imaging data with patient history and laboratory results simultaneously. This integrated approach produces more reliable assessments than any individual input could provide alone.
Autonomous Vehicle Integration
Autonomous vehicles process camera feeds, radar signals, lidar data, and GPS coordinates together. This multi-source approach enables real-time decision-making in complex traffic scenarios.
Relying on vision alone proves insufficient during adverse weather or low-light conditions. The redundancy across modalities ensures safer navigation regardless of environmental challenges.
Customer Support Enhancement
Customer support platforms interpret user queries across formats—analyzing product photos alongside text descriptions. This dual-input approach reduces resolution time significantly.
When customers upload images with their questions, systems examine visual details while processing the specific inquiry. The result delivers more targeted solutions than text-only helpdesk systems achieve.
AI Multimodal: Understanding How Multiple Data Transform Modern AI Systems
Real-World Examples of Multimodal AI Models
Several advanced models illustrate AI Multimodal capabilities:
Google Gemini handles text, images, audio, and video in context-rich interactions, enabling smarter search and content production.
OpenAI’s GPT-4V and successors expand vision-language abilities, allowing users to upload images or diagrams and receive informed responses.
Meta’s ImageBind and Anthropic Claude models integrate complex modalities, including depth and thermal inputs, for enhanced interpretation tasks.
These models show how multimodal processing delivers insights that single-input systems cannot.

CREATE INFOGRAPHIC IMAGE FOR AI Multimodal: Understanding How Multiple Data Transform Modern AI Systems
Advances in Vision-Language and Multimodal Learning
Vision-language models represent a key subset of multimodal AI, enabling systems to jointly interpret images and text. Shared representation spaces allow machine agents to caption images, answer detailed questions about visual content, and interact with video frames in context. These capabilities are foundational to modern multimodal reasoning—improving accuracy and relevance of AI outputs in complex environments.
Challenges in AI Multimodal Development
Integrating diverse input streams introduces technical challenges such as data alignment, synchronization across modalities, and ensuring consistent semantic interpretation. Training data must be carefully curated and annotated to bridge the gap between text, visuals, and sound effectively. Furthermore, computational cost and hardware demand increase with each modality incorporated. Overcoming these obstacles is essential to broad adoption of multimodal systems.
Emerging Use Cases Across Industries
Multimodal AI is transforming the way machines interact with humans and environments. In retail, visual search and voice-guided recommendations improve customer engagement. In education, models can review student submissions that include diagrams, text, and spoken explanations, yielding multidimensional feedback. Medical systems use multimodal analysis to correlate patient notes with imaging for sharper diagnosis support. Each use case highlights the value of cross-modal intelligence in real-world settings.
Conclusion
AI-Multimodal marks a turning point in machine intelligence, enabling systems to interpret the world in richer and more contextually relevant ways. By integrating text, vision, audio, and video, these models bring machines closer to human-like understanding. As models like Google Gemini and the GPT series continue advancing, the opportunities for practical application across business, healthcare, and creative media will grow. AI-Multimodal systems are paving the way for more intuitive and impactful human-machine interaction.
Recommendation
To explore AI-Multimodal firsthand, start with tools that support vision-language interaction and multimodal queries. Experiment with models that accept both images and text in one prompt to see how outputs change with rich input. For organizations, assess current workflows where visual, spoken, and written data coexist—customer service chat, product catalogues, or medical records—and pilot multimodal solutions in those areas. This approach builds meaningful experience while identifying high-impact deployments.
FAQs
What is AI Multimodal?
Multimodal AI systems can process and combine multiple types of data like text, images, and audio to produce richer results.
How does multimodal AI improve machine understanding?
By correlating diverse inputs, it enables more precise context and nuanced outputs than single-input models.
Where is AI Multimodal used today?
It is used in healthcare diagnostics, visual search, customer support, and autonomous systems to enhance decisions.



{kind=link}