
AI Accelerators: The Hardware Revolution Reshaping Intelligent Computing
Introduction
The term “AI accelerator” appears across technical documentation, industry announcements, and startup funding rounds, but it describes two distinct realities. For chip architects and data center operators, AI accelerators represent specialized silicon—GPUs, TPUs, ASICs, and novel packaging technologies like 3.5D XDSiP—designed to handle the mathematical intensity of neural networks . For founders and developers, AI accelerators function as commercial program that compress go-to-market timelines through credits, mentorship, and infrastructure access. Both meanings converge on the same truth: AI accelerators, whether hardware or program-based, determine who can build, deploy, and scale artificial intelligence effectively. Understanding AI accelerators requires examining both the silicon that powers models and the ecosystems that commercialize them.
What AI Accelerators Actually Are: A Definition under Pressure
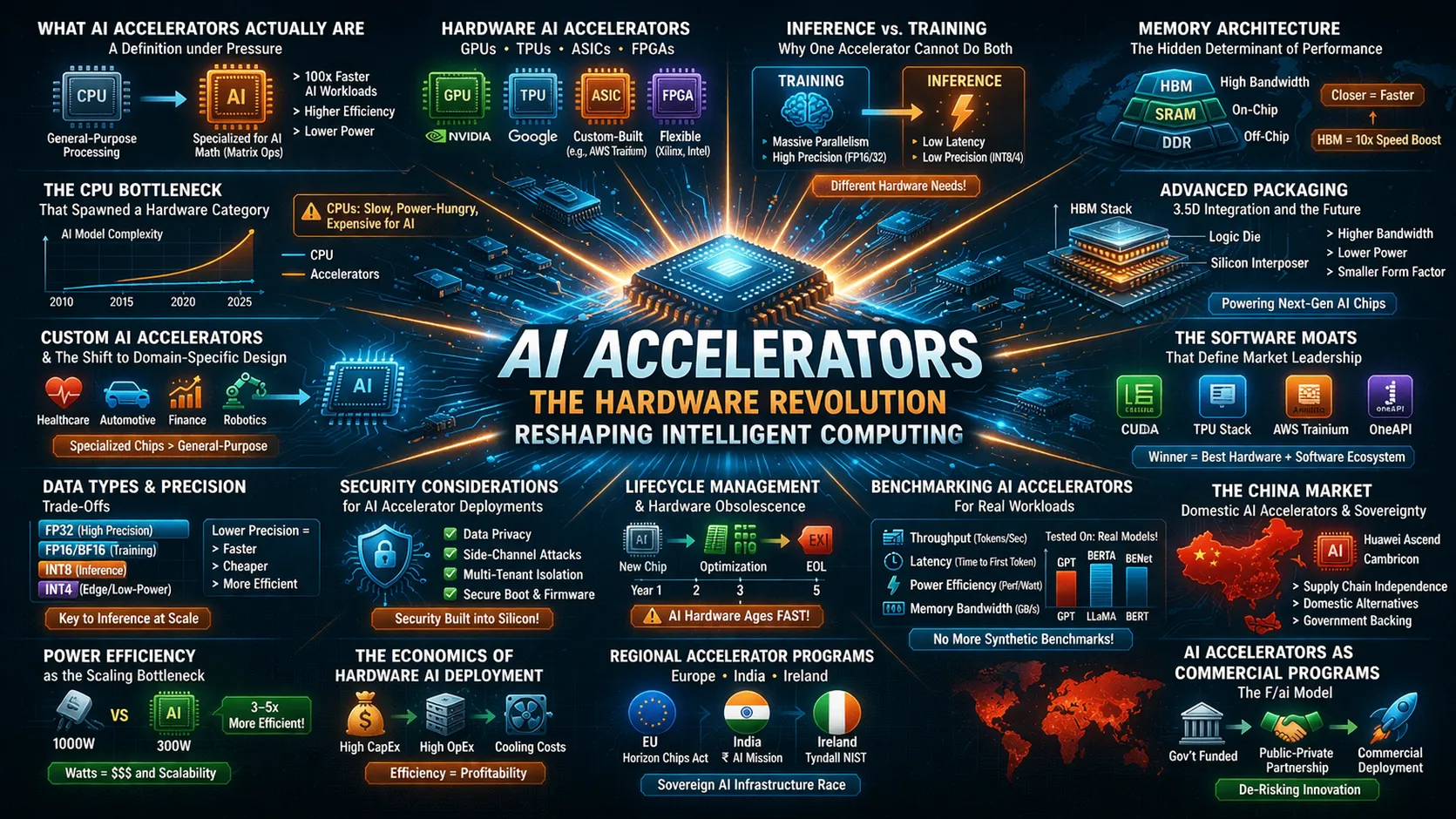
An AI accelerator is a dedicated hardware component or structured commercial program optimized for machine learning workloads. The hardware category includes Graphics Processing Units, Tensor Processing Units, Field-Programmable Gate Arrays, and Application-Specific Integrated Circuits—each designed to perform the parallel matrix operations that neural networks demand. The program category refers to time-bound initiatives that provide startups with compute credits, model access, and mentorship to accelerate commercialization. This dual definition reflects market maturity: as AI moves from research to production, both the physical infrastructure and the business infrastructure require acceleration.
The CPU Bottleneck That Spawned a Hardware Category
Traditional CPUs process instructions sequentially, making them fundamentally mismatched for deep learning workloads. A modern AI accelerator contains thousands of specialized cores designed for simultaneous floating-point operations. This architectural divergence became apparent when researchers discovered that GPUs, originally built for rendering graphics, could train neural networks orders of magnitude faster than CPUs. Today, the performance gap has widened to several orders of magnitude. Organizations serious about AI infrastructure no longer ask whether they need AI accelerators but which combination of accelerator type’s best suits their training and inference requirements.
Hardware AI Accelerators: GPUs, TPUs, ASICs, and FPGAs
The hardware landscape divides into four primary categories. GPUs dominate due to their mature software ecosystems, particularly Nvidia’s CUDA platform, which has become the default development environment for most AI practitioners. TPUs, developed by Google, sacrifice flexibility for efficiency, delivering higher throughput per watt for tensor operations but binding users to specific frameworks. ASICs represent the most specialized category, custom-built for particular workloads. FPGAs offer reconfigurability, allowing organizations to adapt hardware to evolving model architectures. The choice among these involves trade-offs between performance, flexibility, and the software stack required to realize theoretical specifications.
AI Accelerators: The Hardware Revolution Reshaping Intelligent Computing
Inference versus Training: Why One Accelerator Cannot Do Both
Training accelerators priorities raw throughput and the ability to distribute workloads across hundreds of interconnected chips. They require massive memory bandwidth and sustained compute for operations that run for days or weeks. Inference accelerators focus on latency, power efficiency, and cost per prediction. A chip optimized for training a large language model over three weeks looks fundamentally different from one designed to serve millions of predictions per second at sub-millisecond latency. Organizations that deploy training hardware for inference workloads typically operate at two to three times the necessary cost structure. Understanding this distinction separates mature AI infrastructure strategies from experimental approaches.
Memory Architecture: The Hidden Determinant of Performance
Raw compute specifications rarely predict real-world AI accelerator performance. The memory subsystem often determines outcomes. High-bandwidth memory stacked directly on the accelerator die reduces the physical distance data must travel, directly impacting throughput. A compute unit with insufficient memory bandwidth sits idle regardless of its theoretical peak operations per second. The balance between compute capacity, memory bandwidth, and memory capacity defines which models an accelerator can handle effectively. A 100-billion-parameter model demands different memory characteristics than a small vision model running at the edge.
Advanced Packaging: 3.5D Integration and the Future of AI Silicon
Traditional 2.5D packaging, which places multiple chiplets on an interposer, is reaching practical limits as AI workloads demand higher integration. Broadcom’s 3.5D XDSiP platform represents a significant evolution, combining 2.5D techniques with 3D-IC integration using face-to-face technology. This approach delivers a sevenfold increase in signal density between stacked dies and reduces power consumption in die-to-die interfaces by a factor of ten. For organizations building custom AI accelerators, advanced packaging determines achievable performance per watt and the ability to integrate compute, memory, and I/O within constrained physical envelopes.
The Software Moats That Define Market Leadership
Hardware specifications alone do not determine success. The software stacks—compilers, libraries, developer tooling, and framework integrations—creates switching costs that often outweigh raw performance advantages. Nvidia’s CUDA ecosystem remains the most mature, with optimized libraries and documentation that reduce development friction. Competitors offering theoretically superior hardware frequently struggle because developers cannot achieve comparable performance without extensive engineering effort. When evaluating AI accelerators, the question is not just what the chip can do but whether the software enables developers to realize that potential without excessive friction.
The China Market: Domestic AI Accelerators and Supply Chain Independence
US semiconductor export controls have accelerated domestic AI accelerator development in China. Huawei’s Atlas 350, unveiled in March 2026, represents a fully domestically developed inference accelerator equipped with the Ascend 950PR NPU and self-developed HBM memory. The company claims performance 2.87 times that of Nvidia’s H20, a low-end GPU permitted for sale in the Chinese market. Pricing at approximately 110,000 yuan positions it as an alternative for organization struggling to obtain Nvidia hardware. While not yet competitive with cutting-edge offerings globally, these domestic AI accelerators signal a shift toward regionalized AI supply chains.
AI Accelerators as Commercial Programs: The F/ai Model
The term AI accelerator also describes structured programs that compress startup commercialization timelines. Station F’s F/ai accelerator, launched in Paris with partners including OpenAI, Anthropic, Google, Meta, Microsoft, and Mistral, represents an unprecedented collaboration among industry rivals. Each cohort of 20 startups receives more than $1 million in partner credits for compute, models, and services rather than direct funding. The program runs for three months, twice yearly, with a focus on rapid commercialization—helping founders reach €1 million in revenues within six months. This model aligns incentives: labs gain high-quality applications built on their stacks, and startups gain low-cost infrastructure access.
Regional Accelerator Programs: Europe, India, and Ireland
The F/ai model has inspired similar initiatives across regions. Google’s AI First Accelerator program selected 20 Indian startups in September 2025, with 45 percent working on agentic AI and 30 percent on multimodal AI. Participants receive Google Cloud infrastructure, Gemini model access, and technical mentorship. In Ireland, the AI Venture Forge accelerator at PorterShed works closely with MIT and the Irish Centre for High-End Computing, giving startups hands-on access to powerful GPU resources along with the Orbit AI platform to test and validate their ideas in real market conditions. These regional programs reflect a broader recognition that AI commercialization requires both infrastructure access and structured go-to-market support.
The Economics of Hardware AI Accelerator Deployment
Cost structures for AI accelerators involve complex trade-offs between capital expenditure, operational expense, and utilization. Purchasing accelerators provides predictable long-term costs but requires forecasting capacity needs months in advance. Cloud-based consumption matches cost to actual usage but exposes organization to variable pricing and vendor lock-in. The economics shift dramatically based on utilization. A purchased accelerator running at 30 percent utilization rarely achieves cost-effectiveness compared to cloud alternatives. Organizations develop total cost of ownership models that account for hardware, power, cooling, software licensing, and engineering time.
Power Efficiency as the Scaling Bottleneck
Energy consumption has become the limiting factor for large-scale AI deployments. Training a large language model consumes megawatt-hours of electricity, and inference at scale multiplies that consumption across millions of requests. Data center operators increasingly evaluate AI accelerators on performance per watt rather than raw throughput. This drives architectural innovation, from specialized data types that reduce precision without sacrificing model accuracy to advanced packaging that minimizes power lost to data movement. Organizations planning infrastructure must consider ongoing power and cooling costs, which often exceed hardware costs over multi-year horizons.
Data Types and Precision Trade-Offs
Modern AI accelerators support numeric formats beyond standard 32-bit floating-point. Lower precision formats like 16-bit floating-point, bfloat16, and 8-bit integer enable higher throughput and lower memory consumption with minimal impact on model accuracy for inference workloads. Huawei’s Atlas 350 introduces FP4 low-precision computing, sacrificing some data precision to significantly boost processing speed for real-time applications like AI agents. The choice of precision affects both performance and power consumption, sometimes by factors of two or three. Organizations should evaluate whether their models can leverage lower precision effectively.
Custom AI Accelerators and the Shift to Domain-Specific Design
As AI workloads mature, organizations increasingly pursue custom AI accelerators tailored to their specific model architectures and deployment scenarios. Broadcom reports shipping custom compute SoCs built on its 3.5D XDSiP platform for major consumer AI customers, with production scheduled for early 2026. These custom accelerators, sometimes called XPUs, integrate customer-owned processing unit architectures with Broadcom’s IP for memory, network I/O, and advanced packaging. The trend toward domain-specific design reflects the limits of general-purpose accelerators for workloads at extreme scale.
Security Considerations for AI Accelerator Deployments
AI accelerators introduce security considerations distinct from traditional computing infrastructure. Accelerators often have direct memory access capabilities and operate on sensitive model weights and potentially user data. Multi-tenant environments sharing accelerators must ensure isolation between workloads to prevent data leakage. Side-channel attacks targeting accelerator memory or interconnects have been demonstrated in research settings. Organizations should include accelerators in security architecture reviews, considering physical security for on-premises deployments and isolation guarantees for cloud-based usage.
Lifecycle Management and Hardware Obsolescence
AI accelerators evolve rapidly, with new generations delivering substantial performance improvements every two to three years. This pace creates lifecycle management challenges. An accelerator purchased today may be several generations behind within three years, affecting both performance competitiveness and software support. Organizations should plan refresh cycles aligned with workload requirements and consider leasing or consumption-based models to maintain flexibility. Treating accelerators as long-term capital assets often misaligns with the reality of their rapid technological evolution.
Benchmarking AI Accelerators for Real Workloads
Vendor-supplied performance numbers rarely reflect real-world results. Effective evaluation requires testing with actual model architectures, datasets, and deployment scenarios. Factors like model size, batch size, precision requirements, and framework versions all affect performance significantly. Organizations should develop benchmark suites representing their production workloads and run them on actual accelerator configurations. Cloud instances with various accelerators make this testing accessible without large upfront hardware investments. Time invested in proper benchmarking returns multiples in avoided misprocurement.
AI Accelerators: The Hardware Revolution Reshaping Intelligent Computing
Conclusion
AI accelerators exist in two forms: specialized silicon that determines training and inference capabilities and commercial programs that determine who gets infrastructure access. Both are evolving rapidly—advanced packaging pushes hardware limits while collaborative programs reshape startup scaling.
Organizations that treat AI accelerators as strategic infrastructure, evaluated against real workloads, will maintain flexibility as the landscape shifts. Infrastructure decisions today determine AI capabilities for years to come.
FAQs
What is the difference between a hardware AI accelerator and a startup AI accelerator?
A hardware AI accelerator is specialized silicon like GPUs or TPUs optimized for machine learning computations, while a startup AI accelerator is a structured program providing compute credits, mentorship, and infrastructure access to help AI companies commercialize rapidly.
How do I choose between GPUs, TPUs, and ASICs for my AI workload?
Consider your framework compatibility, model architecture, scale requirements, and the software ecosystem maturity. GPUs offer broadest compatibility, TPUs excels within Google’s ecosystem, and ASICs provide maximum efficiency for specific workloads at sufficient scale.
What role do AI accelerator programs play in the broader AI ecosystem?
These programs reduce commercialization barriers by providing early-stage startups with infrastructure credits, technical mentorship, and go-to-market guidance, effectively lowering the capital required to reach revenue milestones.



{kind=link}