SLMs vs LLMs: The Strategic Realignment of AI Architecture
Introduction
The conversation around language models has shifted. For years, the assumption was simple: bigger equals better. More parameters, more data, more compute. That assumption is now being tested in production environments across the UK and USA. Small language models vs large language models are demonstrating that they can handle specific tasks with surprising efficiency, often matching or even outperforming their larger counterparts in narrow domains. This comparison between Small language models vs large language models is no longer theoretical. It is a practical decision facing every technical team building AI applications today. Understanding where Small language models vs large language models fit is essential for cost-effective, privacy-preserving AI deployment.
Core Definition and Primary Entity: What is a Small Language Model?
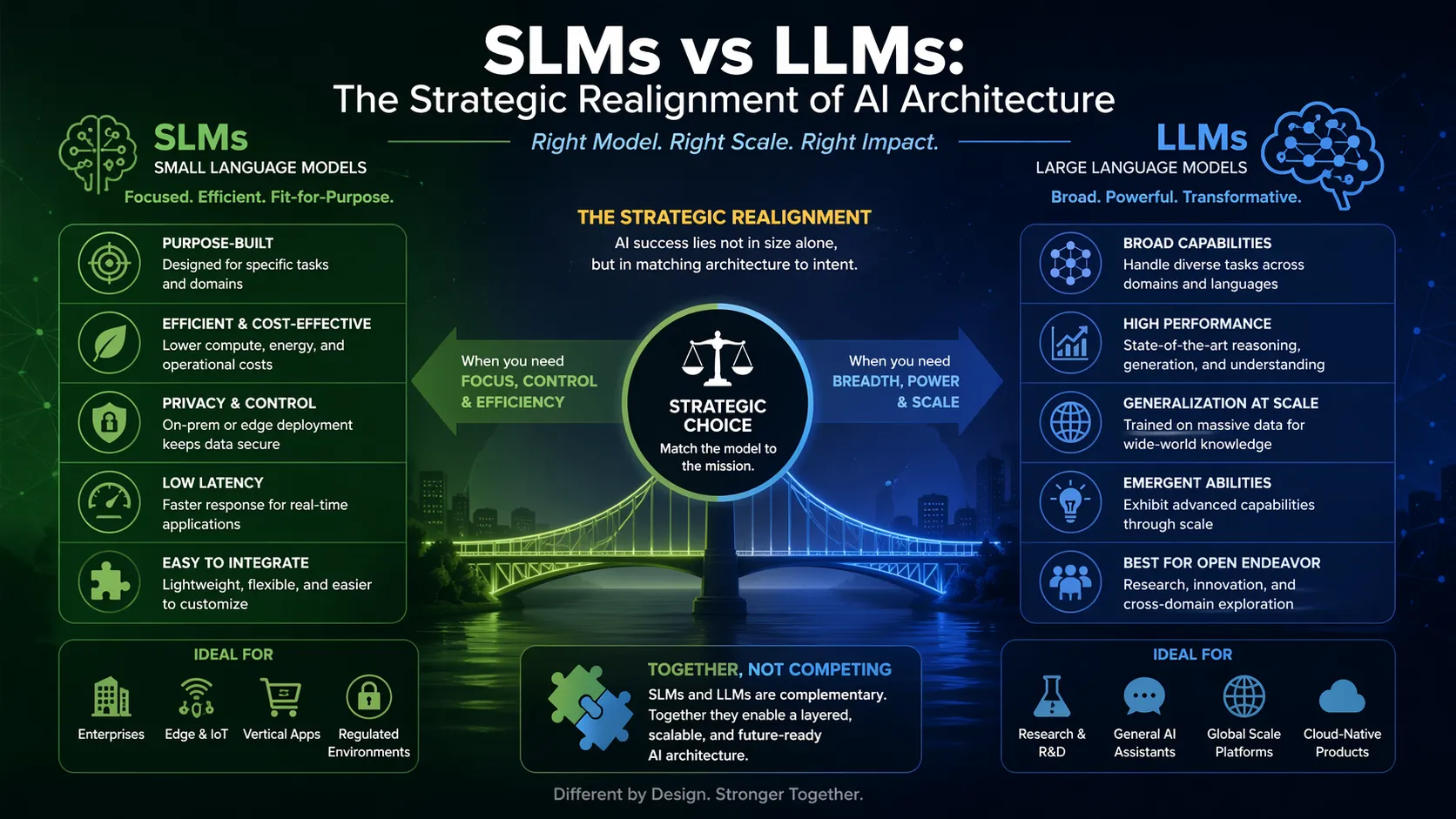
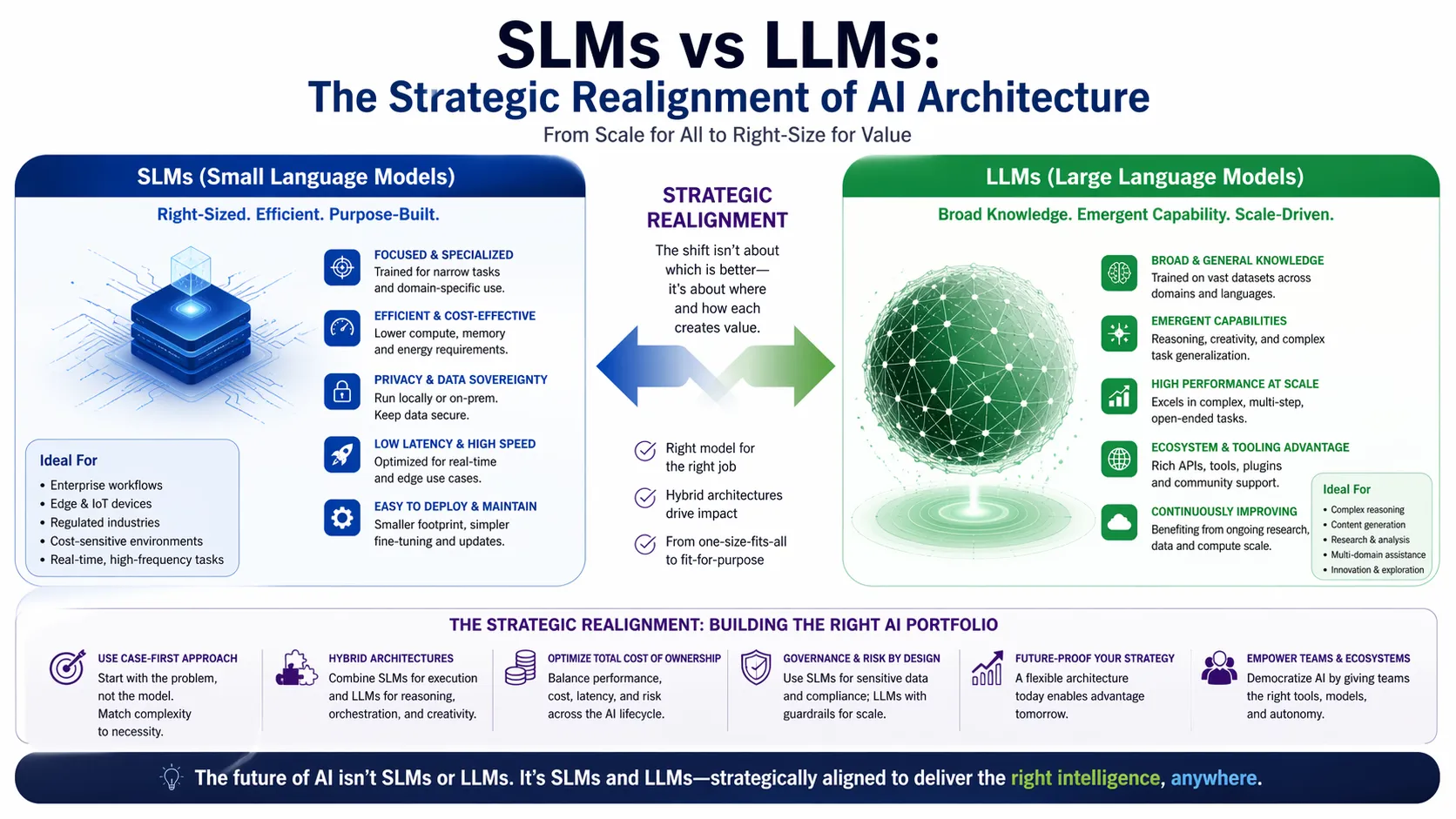
A small language model (SLM) is a generative AI system built on the same transformer architecture as large language models but operates with a significantly reduced parameter count, typically ranging from a few hundred million to approximately ten billion. Unlike their large counterparts that require massive GPU clusters and cloud infrastructure, SLMs are designed for computational efficiency. They are not simply scaled-down copies; they are engineered for resource-constrained environments and targeted task execution.
Defining: The Large Language Model (LLM)
A large language model (LLM) is a general-purpose AI system containing hundreds of billions or even trillions of parameters, trained on internet-scale datasets to achieve broad knowledge generalization. These models are built for versatility and can handle open-ended reasoning, complex code generation, and multilingual translation across diverse domains. However, this broad capability demands significant computational resources, including high-end GPUs, vast memory, and substantial electricity consumption.
SLMs vs LLMs: The Strategic Realignment of AI Architecture
Entity Reinforcement: The Ecosystem of Supporting Technologies
Understanding small language models vs LLMs requires recognizing the supporting entities that enable or constrain them. Key entities include the transformer architecture, which provides the underlying attention mechanism. Other critical concepts are model parameters, inference latency, fine-tuning, retrieval-augmented generation (RAG), quantization, and edge computing. These entities form the technical stack that determines where a model runs, how fast it responds, and how much it costs to operate.
Architectural Divergence: How Scale Dictates Infrastructure
The mechanism separating SLMs from LLMs is primarily resource footprint. An LLM demands scalable, cloud-based processing with specialized GPU arrays to manage massive parallel computations and data transfers. In contrast, an SLM is compact enough to reside on an edge device, a mobile phone, or a standard enterprise server without requiring a dedicated GPU. This architectural constraint changes everything: it defines whether data must leave the premises and whether the system can function offline.
The Efficiency Advantage: Cost, Speed, and Latency Trade-offs
When evaluating small language models vs LLMs, the operational metrics are stark. Serving a model with roughly 7 billion parameters can be 10 to 30 times cheaper in latency and floating-point operations than serving a 70 to 175 billion parameter LLM. SLMs deliver faster inference because fewer parameters mean fewer calculations per token generated. This speed is not a luxury; it is essential for real-time applications like live chat support, robotic process automation, and interactive voice response.
Data Sovereignty and Privacy: The Security Edge of SLMs
LLMs accessed via cloud APIs force organizations to transmit sensitive data to third-party servers, creating compliance challenges and potential breach vectors. SLMs, by contrast, can be deployed entirely on-premises or on local hardware. This containment ensures that proprietary data never leaves the organization’s network, a critical requirement for financial services, healthcare, and legal compliance under GDPR or HIPAA frameworks.
Specialization Over Generalization: The Expert vs. The Generalist
Large language models are trained to be generalists. They have read the internet and can discuss history, write poetry, and debug code. Small language models are specialists trained or fine-tuned on narrow, domain-specific datasets. When a model is trained exclusively on financial reports or customer support logs, it develops a depth of contextual understanding in that niche that a massive, generalist model lacks. In these bounded scenarios, the specialist often outperforms the generalist in accuracy and consistency.
Fine-Tuning and Deployment Agility
Because of their smaller size, SLMs can be fine-tuned on proprietary data with far fewer resources and faster iteration cycles than LLMs. An organization can take a base model, adapt it to internal documentation, and deploy the updated version in a matter of days rather than weeks. This agility allows businesses to maintain control over model behavior and update the system as their data or policies evolve, avoiding the black-box drift that can plague larger, opaque cloud models.
Energy Consumption and Sustainability Implications
The computational demands of LLMs translate directly into high energy usage and a larger carbon footprint. Deploying SLMs offers a greener, more sustainable route to AI adoption. These models consume a fraction of the power typically required for large model inference, allowing institutions to minimize operational costs and carbon footprint simultaneously. For many organizations, this efficiency is not just an environmental win; it is a necessary step to meet internal sustainability mandates.
Evaluative Context: When to Use Small Language Models vs LLMs
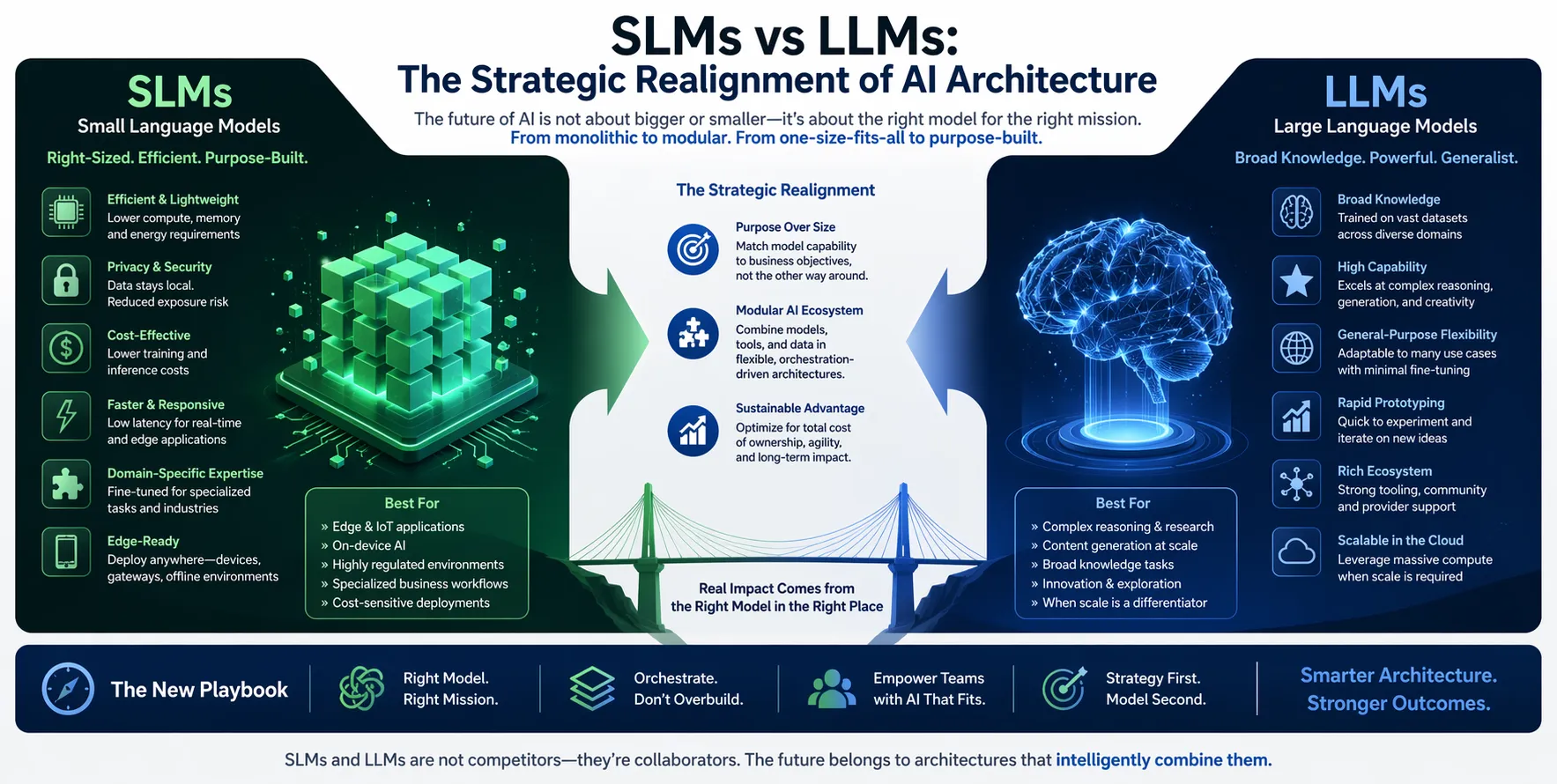
The decision to use small language models vs LLMs should be driven by the scope of the problem rather than the allure of the technology. If the task is narrow, repeatable, and governed by internal rules, such as routing customer support tickets, summarizing internal memos, or classifying financial transactions, an SLM is the superior choice. If the task requires open-ended reasoning, creative content generation spanning multiple topics, or complex strategic analysis, the versatility of an LLM becomes essential.
The Rise of Hybrid and Agentic Architectures
The future of deployment is not an either-or choice. Many sophisticated systems now employ a hybrid architecture where an SLM acts as the efficient “specialist” or “router,” handling 80% of routine requests. When the system encounters a complex, ambiguous, or high-stakes query, it escalates to an LLM. This orchestration, often managed by agentic workflows, captures the speed and low cost of SLMs while preserving the deep reasoning power of LLMs for edge cases.
Mitigating Hallucinations and Improving Predictability
LLMs, with their massive and unfiltered training data, are more prone to generating plausible-sounding but factually incorrect information. SLMs, constrained by their focused training on a specific, verified corpus, tend to produce more predictable and reliable outputs within their domain. This predictability is crucial in business operations where a hallucinated response can lead to financial errors, compliance violations, or customer churn.
SEO Implications: The Language of Search Engines vs. AI Models
For content strategists, small language models vs LLMs creates a new visibility layer. Traditional SEO targets SERP keywords for ranking. LLM optimization targets entities and conceptual density for answer generation. While high-ranking content often overlaps with the foundational language AI models use, LLMs are increasingly prioritizing sources that provide clear, structured, and entity-rich explanations rather than pages optimized solely for keyword density. Visibility is no longer just about ranking; it is about being quotable by AI systems.
Generative Engine Optimization (GEO) for Topical Authority
To ensure content is retrievable by both search engines and AI answer systems, content must be structured with answer-ready blocks and strong entity relationships. AI models prefer concise, factual, and extractable sections. By clearly defining the primary entity and supporting entities early and consistently, content stands a higher chance of being synthesized into an answer. This is the practical application of GEO, where clarity directly impacts whether a model cites or ignores your information.
Cost Analysis: Infrastructure and Operational Spend
The cost differential between small language models vs LLMs is not marginal; it is transformative. Operating a $30/month CPU server running an SLM can replace tens of thousands of dollars in monthly API calls to large model providers for high-volume, routine tasks. API costs scale linearly with usage, but infrastructure costs for a local SLM are fixed. This shift allows businesses to scale AI usage across thousands of employees or millions of daily transactions without incurring runaway variable expenses.
The 2026 Trajectory: Efficiency Over Scale
Industry analysts and technical surveys indicate a clear pivot away from the “bigger is better” paradigm. The focus has shifted from achieving maximum capability at any cost to optimizing for efficiency, cost control, and return on investment. The next generation of AI deployment will be defined by modularity, where teams of small, specialized models operate under the guidance of a few strategic LLMs. This approach aligns AI deployment more closely with traditional software engineering principles of modular design and maintainability.
Security and Compliance in Regulated Industries
In sectors like banking, insurance, and healthcare, the ability to deploy SLMs on-premises is not just a technical preference; it is compliance imperative. LLMs, due to their cloud-based nature and broad data ingestion, introduce significant risk vectors for data leakage. SLMs provide a controlled environment where audit trails are clear, data residency requirements are met, and the model’s access to sensitive information is strictly bounded.
Technical Enablers: Quantization and RAG
The viability of SLMs is enhanced by technical enablers like quantization and retrieval-augmented generation (RAG). Quantization reduces the memory footprint of a model by lowering the precision of its weights, allowing it to run effectively on CPUs. RAG allows an SLM to access a specific, up-to-date knowledge base at inference time, bridging the gap between the model’s static training data and dynamic business information without costly retraining.
SLMs vs LLMs: The Strategic Realignment of AI Architecture
Conclusion
The distinction between small language models vs LLMs represents a maturation of AI deployment strategy. The era of chasing ever-larger parameter counts as a proxy for capability is yielding to an era defined by precision engineering and operational efficiency. Going forward, the organizations that extract the most value from AI will not be those with the biggest models, but those with the best orchestration of the right model for the right task. Evaluate your current and upcoming AI initiatives with this framework in mind. Focus on the specific job to be done, and you will find that the most powerful tool is often not the largest, but the most precisely targeted.
FAQs
What is the main difference between small language models vs LLMs in production?
The primary difference is the resource footprint. SLMs use millions to low billions of parameters and run on CPUs or edge devices, while LLMs use hundreds of billions of parameters and require expensive GPU clusters.
When should I choose an SLM over an LLM for my business?
Choose an SLM when the task is narrow, repeatable, privacy-sensitive, or requires low latency. Choose an LLM for open-ended reasoning, creative generation, or tasks requiring broad world knowledge.
Can small language models replace large language models entirely?
No. SLMs cannot replace LLMs for generalist, open-ended tasks. The most effective enterprise strategies use a hybrid model: SLMs for efficiency and speed, with LLMs reserved for complex, high-value exceptions.



{kind=link}